|
Юрий Гончаров
Новое поколение ЦСП Texas Instruments
ЦСП семейства С5000 Texas Instruments уже зарекомендовали себя как производительные и малопотребляющие изделия для мобильных устройств. В настоящее время Texas Instruments выпустил первую модель третьего поколения ЦСП семейства С5000, построенную на базе недавно объявленного ядра С5000 — TMS320VC5510. Новый ЦСП в 5 с лишним раз производительнее и в 6 раз экономичнее, чем ранее выпущенные процессоры. Обзору этой новой модели ЦСП и нового процессорного ядра, на базе которого она построена, и посвящена эта статья.
ЦСП семейства С5000 Texas Instruments уже зарекомендовали себя как производительные, малопотребляющие и недорогие ЦСП для мобильных устройств, достигнувшие показателя в 0,54 мВт на MIPS при производительности до 100…160 MIPS. ЦСП нового третьего поколения семейства С5000, построенные на новом ядре С55хх, имеют более чем в 5 раз лучшую производительность и более чем в 6 раз меньшее энергопотребление, чем ранее выпускавшиеся ЦСП.
Уже первая младшая модель ЦСП TMS320VC5510 показала рекордное снижение энергопотребления в своем классе. Выпускаемый с начальной тактовой частотой 160 МГц и производительностью 320 MIPS и имеющий на кристалле 320 Кбайт ОЗУ, новый процессор потребляет всего 80 мВт, что составляет половину от энергопотребления в расчете на MIPS от производительности любого другого выпускаемого в настоящее время ЦСП.
В настоящее время выпускается 160-мегагерцовая версия устройства, однако TI планирует в следующем году как поднять частоту до 200 и более мегагерц, так и снизить потребление, выпустив устройство с напряжением питания 1 В. Планируется, что в своем развитии ЦСП С55хх достигнут производительности порядка 800 MIPS при тактовой частоте 400 МГц. При этом энергопотребление ядра снизится до 0,05 мкВт на MIPS, а напряжение питания — до 0,9 В.
Применение нового ядра расширяет возможности построения мощных, компактных и в то же время дешевых и малопотребляющих узлов для ресурсоемких мобильных устройств, обеспечивая:
- новые возможности мобильных Интернет-решений — внедрение в мобильные телефоны возможностей доступа в Интернет и передачи изображений в формате MPEG4;
- внедрение на новые рынки. Большая мощность и соответственно, новые возможности при том же потреблении питания позволяют радикально преобразовать существующие устройства, переводить традиционные аудио- и видеоустройства на новую цифровую базу;
- увеличение функциональных возможностей за счет роста производительности процессора позволяет дать новый уровень функциональности и новую жизнь уже существующим изделиям.
Сравним показатели нового ядра С55х с С54х:
| |
TMS320C54x ЦСП |
TMS320C55x ЦСП |
Улучшение |
| Потребление mW/MIPS |
0.32 |
0.05 |
5x |
| MIPS |
30-160 |
140-800 |
5x |
| MMACs |
30-160 |
140-800 |
5x |
| Размер кода |
|
Переменная длина команд |
30% |
| Функциональные модули |
MAC |
1 |
2 |
|
| ALU |
1 |
2 |
|
| ACC |
2 |
4 |
|
| Регистры данных |
0 |
4 |
|
| Выборка команд |
16 разрядов |
32 разряда |
|
| Длина команд |
Фиксированная 16 разрядов |
Переменная 8-48 разрядов |
|
Суммарно по сравнению с 120-мегагерцовым процессором C54x уже первый реально выпущенный 300-мегагерцовый представитель нового семейства дает выигрыш в 5 раз при потреблении в 1/6 от ядра С54х. При этом за счет использования новой системы команд переменной длины размер кода уменьшается на 30 %.
За счет чего же достигается столь значительный прирост производительности?
Рассмотрим общую структуру ядра С55хх, показанную на рис. 1.:
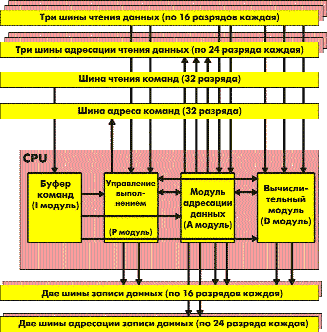
Рис. 1. Структура процессорного ядра С55хх
Ядро процессора построено по традиционной модифицированной Гарвардской архитектуре и содержит 4 функциональных модуля:
- вычислительный модуль (D unit);
- модуль адресации (A unit);
- модуль декодера команд (I unit);
- модуль управления выполнением (P unit).
Модули объединены между собой и с остальными ресурсами ядра большим количеством шин:
- тремя 16-разрядными шинами чтения данных;
- тремя 24-разрядными шинами адреса для шин чтения данных;
- двумя 16-разрядными шинами записи данных;
- двумя 24-разрядными шинами адреса для шин записи данных;
- 32-разрядной шиной чтения команд;
- 24-разрядной шиной адреса для чтения команд.
Такое количество шин обеспечивает высокую степень взаимной независимости функциональных модулей и вычислительных ресурсов и допускает параллельное выполнение сложных многопотоковых команд обработки данных без снижения производительности.
Ядро процессора С55хх обладает большим количеством вычислительных ресурсов и допускает параллельное выполнение операций как различными функциональными модулями ядра, так и различными ресурсами внутри модулей. При этом параллельность выполнения для более полного использования ресурсов процессора может определяться как программистом, так и компилятором при трансляции программы с языка высокого уровня.
Вычислительный модуль (D-модуль)
Это основной вычислительный блок ядра, его сердце. В ядре С55хх установлен существенно расширенный вариант уже отработанного и хорошо зарекомендовавшего себя ядра С5000. В состав вычислительного ядра входят два МАС-модуля. Причем МАС-модуль — это не просто умножитель, а законченная вычислительная единица, не требующая для выполнения операции умножения и сложения дополнительного АЛУ. В МАС-модуль входит умножитель 17х17, 40-разрядный сумматор/вычитатель и 40- или 32-разрядный ограничитель. Для промежуточного хранения данных используется четыре 40-разрядных аккумулятора.
В состав D-модуля также входит отдельное 40-разрядное АЛУ, которое может выполнять либо одно действие над 40-разрядным аккумулятором, либо выполнять параллельно две 16-разрядных операции. Кроме работы с аккумуляторами, АЛУ может получать непосредственные значения из I модуля (константы, входящие в состав команд) и работать напрямую с памятью, регистрами A- и P-модулей.
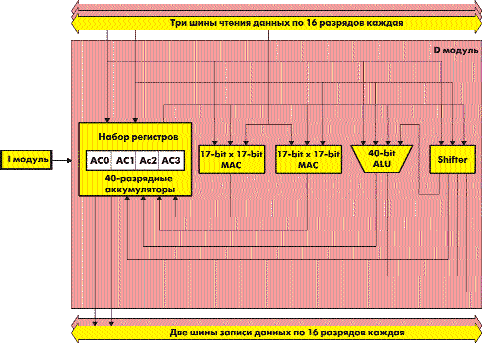
Рис. 2. Структура вычислительного модуля (D-модуля)
Следует отметить и отдельный 40-разрядный сдвигатель, которые позволяет производить одновременный сдвиг 40-разрядного значения аккумулятора на любое число разрядов — до 31 разряда влево и до 13 разрядов вправо.
Разрядность вычислительного модуля больше разрядности самого процессора — умножители имеют разрядность 17х17, а накопительные регистры, АЛУ и сдвигатель — 40-разрядные. Такое увеличение разрядности позволяет существенно снизить накапливающиеся ошибки округления и усечения при длительных целочисленных вычислениях. Причем увеличенная разрядность MAC-модулей, АЛУ и аккумуляторов позволяет избавиться от большей части проблем с переполнением и соответствующим ограничением результата.
Однако построить параллельное вычислительное ядро — еще не значит построить законченный ЦСП, иначе все производители давно бы поставили в ядро несколько десятков МАС-модулей и решили этим задачу достижения максимального быстродействия. У параллельного вычислительного ядра имеются две основные проблемы: распараллеливание задачи и обеспечение непрерывности загрузки мощного вычислительного ядра, то есть непрерывность подачи данных и съем результатов. Оставив первую проблему за рамками данной статьи как проблему построения алгоритмов, рассмотрим подробнее вторую, непосредственно касающуюся архитектуры ЦСП.
На первый взгляд, простым решением являлось бы увеличение числа шин подачи и съема данных для параллельного вычислительного ядра, однако шины данных должны подключаться к памяти. Здесь и начинаются проблемы — в идеале память имеет всего одну шину. Следующий шаг — память с двойным доступом — значительно более дорогое и объемное устройство. Память с тройным доступом уже не применяют — слишком сложная ячейка. Вспомним и еще одно обстоятельство: всю память для любой задачи внутри микросхемы разместить сложно — приходится работать и с внешней памятью, а у внешнего ОЗУ шина всего одна, плюс ограничения по скорости обмена, плюс ограничения по разрядности, поскольку количество выводов у корпуса ограничено и желательно его минимизировать.
При нарушении баланса между вычислительным ядром и памятью получаем печальный опыт процессоров x86, когда разницу между 700-мегагерцовым процессором и 100-мегагерцовой памятью пытаются сгладить путем установки маленькой, но быстрой кэш-памяти первого уровня, затем более объемной, но менее скоростной кэш-памяти второго уровня, а затем еще более объемной, но еще менее скоростной кэш-памяти третьего уровня. Возможно, что такое решение и проходит в процессорах общего назначения, но никак не подходит для задач ЦОС, работающих с потоками данных, для которых скорость работы системы вырождается до скорости обмена с конечным ОЗУ.
Посмотрим, как в процессорах семейства С55хх решается описанная проблема.
Мощность ядра С55хх определяется сбалансированной архитектурой, обеспечивающей максимальную загрузку вычислительного ядра в условиях реальной работы. Решение проблемы подачи и съема данных для вычислительного ядра заключается в продуманном распределении шин памяти, а также в принятии специальных решений по сокращению количества циклов доступа к ОЗУ как для основных, так и для резервных операций, например, за счет сокращения циклов на выборку команд и на сохранение промежуточных результатов. Архитектура позволяет оптимально загрузить вычислительное ядро без чрезмерного усложнения подсистемы памяти.
Вернемся к рассмотрению структуры ЦСП. Ядро С55х имеет 5 шин данных по 16 разрядов — три шины чтения данных и две шины записи данных, то есть может обеспечить одновременную выборку трех 16-разрядных слов и запись двух 16-разрядных и одного 32-разрядного слова. При непрерывном выходном потоке на два умножителя приходятся две шины записи, а при накопительных операциях — одна, но большей разрядности. Рассмотрим входные шины: на два МАС-модуля приходятся три шины — по одной к каждому модулю и одна общая. При ближайшем рассмотрении на такую, казалось бы, неполную архитектуру достаточно оптимально с естественным распараллелеливанием укладываются простые и известные задачи. Приведем несколько примеров.
- КИХ-фильтр с симметричными коэффициентами: на раздельные шины подаются части потока данных, а на общую — одинаковый набор коэффициентов, при этом параллельно считаются половинки фильтра, а в конце прохода суммируется результат.
- Любая многоканальная обработка: по общей шине подается входной поток данных, а по раздельным шинам — одновременно два набора коэффициентов. Результаты либо накапливаются в аккумуляторе, либо выводятся двумя потоками в память. Причем, имея запас по производительности, можно одновременно, при помощи мощного адресного блока, обрабатывать 4 канала, сохраняя результат в 4 аккумуляторах.
- БИХ-фильтр: одновременная обработка прямого и обратного потоков.
Как видно из приведенных примеров, использование параллельной обработки даже на базовых операциях при работе в С55хх не вызывает трудностей при распределении потоков данных.
Теперь вспомним про память, к которой ведут все потоки данных, и оценим, возможно ли обеспечить реальную пропускную способность для пяти вышеназванных шин при внутреннем 16-разрядном ОЗУ? Причем рассматривать будем не некое абстрактное процессорное ядро, а реально выпускаемый ЦСП TMS320VC5510. На кристалле 'VC5510 размещено 160 К 16-разрядных слов ОЗУ, из них 64К с двойным доступом (DARAM) и 256 К с одинарным доступом (SARAM).
Одна из основных особенностей подсистемы памяти ЦСП: весь массив памяти разбит на отдельные блоки — восемь блоков DARAM по 4Кх16 и 32 блока SARAM по 4Kx16. Блок памяти представляет собой законченный модуль ОЗУ со своим дешифратором адреса, схемой управления, шиной адреса, шиной чтения данных и шиной записи данных. Каждый блок DARAM имеет по две шины данных, две шины адреса и две шины управления и обеспечивает одновременно проведение двух операций чтения, или двух операций записи, или одной операции чтения и одной операции записи. Каждый блок SARAM обеспечивает проведение одной операции чтения или одной операции записи. Ключевое слово здесь каждый, то есть можно параллельно обращаться к нескольким блокам DARAM или SARAM и выполнять одновременно несколько операций.
Фактически между ядром и памятью размещен коммутатор, к которому с одной стороны подходят шесть линий адреса и данных от ядра (в том числе и шина чтения команд), 6 каналов DMA и расширенный HPI, а с другой стороны суммарно несколько десятков шин от блоков памяти, плюс шины интерфейса внешней памяти (EMIF).
Имея 8 блоков DARAM и 32 блока SARAM + EMIF, одновременно можно выполнить 8х2+32 + 1 = 49 операций с различными участками ОЗУ, а шин от вычислительно ядра подходит всего-то 12. Реально такое количество не нужно, но разбиение памяти на мелкие участки, во-первых, увеличивает быстродействие за счет уменьшения объема дешифратора адреса и самого поля ОЗУ, а во-вторых, упрощает распределение параллельных потоков обмена по разным блокам памяти, что минимизирует вероятность конфликтов при обращении к одному и тому же участку памяти.
Не стоит забывать, что малый объем блока выгоден и с точки зрения его реализации — снижается размер поля памяти, что ведет к снижению емкости внутренних шин, а следовательно, к снижению энергопотребления.
Таким образом, видно, что архитектура ядра С55хх позволяет реально обеспечить максимальную производительность не на специально построенных под его архитектуру тестовых примерах и вычислительных моделях, а на реальных задачах обработки общего вида.
Модуль адресации (A-модуль)
Продолжим рассмотрение структуры ядра С55хх. Для обеспечения работы с большим количеством потоков данных требуется мощный модуль адресации, который в ядре С55хх выделен в отдельный функциональный узел — A-модуль. Структура его показана на рис. 3.
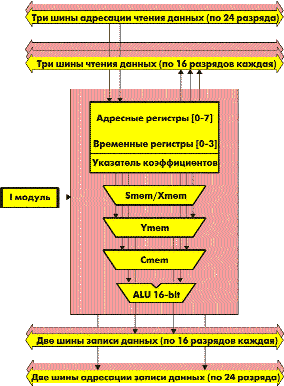
Рис. 3. Структура модуля адресации (D-модуля)
В своем развитии модуль адресации перевоплотился в законченный отдельный процессор со своими регистрами и своим АЛУ и, фактически, со своей программой, задаваемой адресными полями команды или специальными командами для A-модуля.
A-модуль содержит: 16-разрядное АЛУ,
8 адресных регистров, 4 временных регистра, регистры указателей и кольцевых буферов.
А-модуль управляет 5 адресными шинами по 24 разряда — тремя шинами чтения данных и двумя шинами записи данных. Причем все индексные регистры 24-разрядные, доступ ко всему адресному пространству производится напрямую, без какого-либо дополнительного деления на сегменты и т. п.
А-модуль имеет 8 адресных регистров и
5 регистров для организации кольцевых буферов и обеспечивает широкий набор режимов адресации для оптимизации подачи и съема данных для вычислительного модуля.
Система выборки и декодирования команд
Вычислительный модуль вместе с блоком адресации необходимо непрерывно снабжать потоком управляющей информации. Для этого существует система выборки и дешифрации команд, которая в ядре С55х построена по новой схеме и состоит из модуля декодера команд (I-модуль) и модуля управления выполнением (P-модуль).
Модуль декодера команд (I-модуль) выполняет выборку команд из памяти и форматирование потока инструкций для остальных трех модулей (P-модуля, A-модуля и D-модуля).
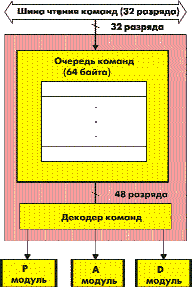
Рис. 4. Структура модуля декодера команд (I-модуль)
В ЦСП семейства С55хх применен новый подход к системе управления — новая, революционная для ЦСП стратегия выборки команд. Вместо прямой выборки из памяти команды фиксированного размера, равного одному, двум или трем словам применяется система команд переменной длины от 1 до
6 байт при фиксированной ширине выборки команд из памяти.
Переменная длина команды — важное нововведение ядра С55хх, позволяющее одновременно использовать и длинные, сложные команды для операций обработки, максимально использующие возможности ядра, и в то же время — использовать предельно короткие команды для операций управления.
Суммарно выигрыш по объему кода при переходе от команд фиксированного размера ядра С54х к командам переменной длинны ядра С55х может достигать 30 %.
Еще одно нововведение — расширенная шина выборки команд.
В ядре С55хх I модуль считывает из памяти команд по 32 бита за одну выборку и размещает считанные команды в буфере емкостью 64 байта (то есть в буфере может быть от 10 до 64 команд), которые затем декодируются и параллельным потоком, шириной до 6 байт поступают на исполняющие модули.
Что дает суммарное использование широкой шины выборки совместно с буфером команд? Во-первых, уменьшается количество обращений к ОЗУ за счет повышенной ширины выборки.
Во-вторых, становится возможным выполнять блоки команд, помещающиеся в буфер, вообще без обращений к памяти команд (локальное повторение), что весьма существенно с точки зрения производительности. Не стоит забывать и о том, что процессор ориентирован на мобильные устройства, а любое обращение к шине — это переключение мощных буферов, приводящее к скачку потребления. То есть уменьшение количества обращений снижает и энергопотребление устройства. Отметим, что применение буфера команд на таком простом примере, как фильтр, может сократить количество обращений к ОЗУ примерно на 30–50 %.
Еще одним преимуществом буфера команд является возможность прогностической выборки при условных изменениях выполнения программы (условный переход, обращение и т. п.). При этом не тратится время на такты очистки конвейера.
Отметим, что I-модуль не занимается динамическим перераспределением последовательности выполнения команд, находящихся в буфере. Это делает заранее определимым и предсказуемым время выполнения программы, что весьма важно при разработке и выполнении приложений реального времени.
Модуль управления выполнением (P-модуль)
Контролирует последовательность и процесс выполнения команд. Он формирует адрес для выборки команд из памяти при последовательном выполнении, при формировании аппаратных циклов, условных переходов, условного выполнения, при работе с подпрограммами и при обработке прерываний.
P-модуль генерирует полный 24-разрядный адрес и может напрямую адресоваться к байтовым командам без выравнивания. Использование 24-разрядного адреса позволяет работать со всей адресуемой памятью команд размером до 16М 32-разрядных слов.
P-модуль оптимизирован на максимально эффективное выполнение программы с минимальными нарушениями режима работы конвейера. Логика генерации адреса P-модуля независима от остального ядра. Она позволяет для минимизации задержек определять адрес условного перехода при нахождении условия тестирования еще внутри конвейера. Модуль управления выполнением является параллельным устройством, позволяющим выполнять команду управления выполнением и команду обработки данных за одну фазу выполнения.
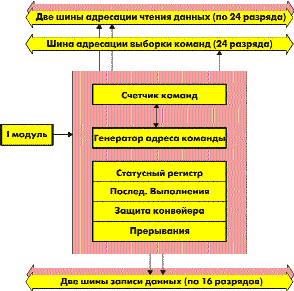
Рис. 5. Структура модуля управления выполнением (Р-модуль)
Еще одним дополнением P-модуля является наличие логики предсказания ветвления для минимизации простоя конвейера при выполнении условных переходов.
Модуль выполнения также отвечает за обеспечение вызова и возврата подпрограмм и прерываний. При этом обеспечиваются функции быстрого вызова и возврата при обработке прерываний, а также система сохранения и восстановления контекста программы. Совместно со стеком, разделенным на стеки данных и команд, эти возможности позволяют легко реализовывать на С55хх мощные операционные системы реального времени с малым временем отклика. Фактически, входящие в состав технологии eXpressDSP средства DSPBios и являются прототипом такой системы.
Интерфейс внешней памяти
Следует особо обратить внимание на этот функциональный узел ЦСП. Процессоры на базе ядра С55хх имеют новый 32-разрядный интерфейс внешней памяти EMIF. Помимо традиционной асинхронной памяти, EMIF обеспечивает прямую поддержку скоростной синхронной памяти типа SBSRAM и SDRAM, работающей на половинной или на полной частоте процессора, что позволяет подключать к процессору десятки мегабайт скоростной и относительно дешевой памяти. Для примера:
1 Мбайт 10–12 нс SRAM — это 4 корпуса, стоимостью около $20–40 за корпус и потреблением порядка 100–200 мA за корпус. При этом еще нужно разместить эти корпуса на плате, развести все шины и заставить стабильно работать на 100 МГц в принципе асинхронное устройство, что является не самой простой задачей. Теперь берем 2 корпуса SDRAM емкостью 64 Мбит и рабочей частотой 133 МГц и получаем за вдвое меньшую цену в 16 раз больше более быстрой (на 30 %) памяти. А ведь есть и 166-мегагерцовая SDRAM, как будто специально сделанная для 300-мегагерцовых ЦСП. При этом SDRAM и SBSRAM имеют изначально спроектированные для работы на высоких скоростях синхронные интерфейсы.
Снижение потребления
Поскольку семейство С55х ориентируется на мобильные устройства, то при его проектировании очень важное место уделялось мерам по снижению потребления. В конструкцию ЦСП заложен ряд решений, которые позволяют вывести процессор на фактически новый уровень снижения потребления. Одним из немаловажных факторов является высокая вычислительная мощность ядра, позволяющая производить параллельно несколько операций, тем самым уменьшая количество активных тактов процессора на выполнение задачи.
Следующим преимуществом архитектуры является уменьшение количества циклов доступа ко внешней и внутренней памяти. Поскольку цикл доступа к памяти — относительно энергоемкая операция, то их минимизация существенно сказывается на общем потреблении устройства. В качестве мер по минимизации циклов доступа можно отметить уже упоминавшиеся 32-разрядную внешнюю шину памяти и 32-разрядную выборку команд, а также переменную длину команд, позволяющую существенно минимизировать количество кода для описания задачи, сократив число тактов для его выборки. Также уменьшению количества циклов выборки из памяти способствует буфер команд, позволяющий выполнять операции внутреннего повторения достаточно сложных функций, работающий вообще без обращения к памяти команд. Следует также вспомнить и преимущества с точки зрения энергопотребления структуры малых блоков ОЗУ.
Кроме общих архитектурных решений, низкому потреблению С55хх способствует и специальный набор функций по управлению энергопотреблением отдельных функциональных узлов. Ядро С55хх автоматически управляет потреблением размещенной на кристалле периферии и памяти. Это управление полностью автоматизировано, прозрачно для пользователя и никаким образом не влияет на производительность выполняемого приложения.
Если к блоку памяти нет доступа, то он автоматически переводится в состояние малого потребления. При затребовании доступа блок памяти автоматически возвращается в рабочее состояние без возникновения каких-либо задержек. Казалось бы, это просто, однако вспомним, что микросхемы быстродействующего статического ОЗУ имеют одну неприятную особенность — достаточно высокое потребление и в статическом режиме, поэтому такой старт без задержки с практически нулевым потреблением в выключенном режиме является не совсем простой операцией.
Аналогично ядро С55хх управляет и состоянием встроенной периферии — выводя ее из состояния низкого потребления только по мере надобности.
Еще одно слагаемое снижения энергопотребления — ручное включение и отключение функциональных узлов процессора. В дополнение к общим режимам снижения потребления IDLE, ядро С55хх имеет специальный регистр, разряды которого отвечают за перевод функциональных модулей процессора в состояние низкого потребления и возврат их к активной работе простой установкой и сбросом битов в регистре. Каждый функциональный модуль — CPU, DMA, периферия, интерфейс внешней памяти (EMIF) и тактовый генератор — может быть включен или отключен независимо от остальных модулей.
Все эти меры позволили процессорам семейства С55хх приблизиться к рекордной планке — 0,05 мВт на MIPS.
Совместимость с предыдущими моделями
При выпуске нового мощного процессорного ядра С55хх фирмой Texas Instruments ставилась цель не просто взять новый рубеж производительности и потребления, но и предоставить все эти новые возможности разработчикам семейства С5000. Необходимо не просто выбросить новую модель на рынок, но и обеспечить плавный переход на нее всех уже наработанных решений от теперь уже предыдущего лидера семейства — ядра С54хх. Для обеспечения совместимости ядро С55х поддерживает выполнение программ для ядра С54хх, обеспечивая, процитируем TI, «идентичные до бита результаты». При этом просто замена используемого процессора с С54х на С55х без переделки программы уже дает улучшение по производительности и по потреблению питания за счет преимуществ нового ядра. А для программ, написанных по рекомендации TI на языке высокого уровня С, с использованием технологии eXpressDSP для использования всей мощности нового процессорного ядра требуется только перекомпилировать код для нового процессора.
В заключение можно сказать, что Texas Instruments в очередной раз подтвердила свое положение лидера индустрии, выпустив мощный и малопотребляющий ЦСП, установивший новый промышленный уровень параметров для устройств подобного класса.
Процессор С55хх — это продуманное и сбалансированное решение, позволяющее всем его элементам максимально использовать заложенные в них конструктивные возможности при выполнении реальных практических задач.
Остается только ждать прихода устройств на базе нового DSP в нашу повседневную жизнь. Судя по тем темпам, с которым фирма TI прошла всю цепочку от анонсированного ядра до первого выпущенного представителя семейства — TMS320VC5510, и по его реальным параметрам, ждать осталось весьма и весьма недолго.
Более подробную информацию о ЦСП нового поколения можно получить на сервере фирмы Texas Instruments по адресу: http://dspvillage.ti.com/docs/dspproducthome.jhtml
Свежие новости и обзоры новых DSP и других продуктов от Texas Instruments DSP можно получить на сервере подразделения Texas Instruments фирмы SCAN по адресу http://www.texas.ru.
ti@scan.ru
|


