|
Владимир Стешенко, к. т. н.
Школа схемотехнического проектирования устройств обработки сигналов
Занятие 6.
Реализация вычислительных устройств на ПЛИС.
Слишком много матросов потопят корабль.
Бонсеньор, «Изречения и сентенции»
Sine inversione
Как правило, современные устройства обработки сигналов предполагают наличие цифрового вычислителя, обеспечивающего реализацию алгоритма обработки сигнала. В этом занятии школы мы рассмотрим некоторые аспекты, связанные с реализацией алгоритмов умножения и цифровой фильтрации, пригодных к реализации на ПЛИС.
Как известно, при реализации цифровой обработки обычно требуется выполнение четырех основных операций — сложения, перемножения двух сигналов, умножение на константу и накопление. Реализация операции умножения аппаратными методами всегда являлась сложной задачей при разработке высокопроизводительных вычислителей. Аппаратная реализация алгоритма умножения предназначена в первую очередь для получения максимального быстродействия выполнения этой операции в устройстве. На ПЛИС можно разрабатывать и реализовать умножители с быстродействием более 100 МГц.
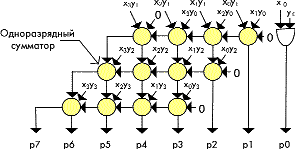
Для операндов небольшой разрядности (4 и менее) наиболее просто реализуется структура простого матричного суммирования (рис. 1). Она формирует параллельный умножитель как массив одноразрядных сумматоров, соединенных локальными межсоединениями, при этом общее число сумматоров напрямую определяется разрядностью множимого и множителя.
Так, полный параллельный умножитель 4x4 требует для своей реализации 12 сумматоров. При дальнейшем наращивании разрядности матрица одноразрядных сумматоров значительно разрастается, одновременно увеличивается критический путь распространения сигнала переноса, соответственно ограничивается быстродействие, и реализация умножителя становится нерациональной.
Одним из способов уменьшения аппаратных затрат служит использование быстрых алгоритмов умножения, например алгоритма Бута [1]. В соответствии с ним определенным образом анализируются парные биты множителя, и в зависимости от их комбинации над множимым выполняются некоторые преобразования.
При реализации умножителей основную задержку в процесс формирования произведения вносит суммирование частичных произведений. Уменьшение их числа сокращает время суммирования. При построении алгоритма Бута используются следующие идеи.
Пусть требуется вычислить произведение вида
Непосредственное вычисление этого соотношения связано с вычислением частичных произведений вида Abi2i. Число таких произведений равно разрядности множителей. Очевидно следующее соотношение.
С использованием этого соотношения возможно осуществить прореживание последовательности степеней в сумме частичных произведений. Можно, например, исключить четные степени. Такое исключение позволяет не только исключить значения оставшихся частичных произведений, но и сокращает их число вдвое, что, естественно, ускоряет вычисление произведения. Единственное, что нам нужно сделать, — расширить разрядную сетку, введя слагаемое b-12-1, чтобы построить представление для члена со степенью 20. Тогда частичные произведения примут вид:
Таким образом, число частичных произведений уменьшилось в два раза, поэтому алгоритм Бута иногда называют алгоритмом умножения сразу на два разряда.
Для всех значений bi+1, bi, bi-1 можно составить таблицу частичных произведений (табл. 1).
Ниже рассмотрим пример построения перемножителя 12x12 разрядов (табл. 2).
Как видно из табл. 2, выполняемые над множимым действия отличаются для двух старших бит, один из которых знаковый. Подобная коррекция позволяет осуществлять операцию умножения над числами в дополнительном коде.
Сформированные частичные произведения, представляющие собой результат преобразования множимого, необходимо суммировать с соответствующим весовым фактором. Результатом их суммирования по алгоритму простого матричного умножителя и будет конечный продукт произведения двух операндов. Наиболее приемлемым для реализации на ПЛИС является алгоритм на основе иерархического дерева многоразрядных масштабирующих сумматоров. При этом достигается сокращение аппаратных затрат по сравнению с параллельным матричным умножителем до двух раз.
Пример реализации данного решения для случая 12-разрядных операндов приведен на рис. 2. В данной схеме выбор соответствующего преобразования множимого Y осуществляется мультиплексором на основании анализа парных бит множителя X в соответствии с табл. 3. Входные значения мультиплексоров 0 и Y подаются непосредственно, значение 2Y формируется сдвигом множимого на один бит, а 3Y формируется путем сложения Y и 2Y.
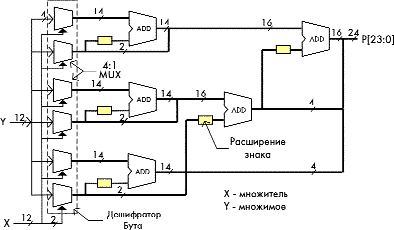
Сумматоры ADD осуществляют суммирование частичных произведений, причем их разрядность для разных ступеней иерархии неодинакова. На каждом шаге суммирования, как видно, имеется несколько сквозных бит, непосредственно дополняющих выходные значения сумматоров. За счет них и за счет битов расширения знака осуществляется необходимое масштабирование результата. Размерность произведения P в конечном итоге равна сумме размерностей операндов.
За счет регулярности приведенной структуры быстродействие можно резко повысить путем введения конвейеризации каждой ступени. При этом разделяются конвейерными регистрами как сумматоры, так и мультиплексоры. Выигрыш в быстродействии благодаря данному решению оказывается особенно ощутимым для большой разрядности операндов.
Другой операцией, характерной для реализации устройств ЦОС, является умножение на константу. Для перемножения двух переменных достаточно иметь таблицу произведений множимого, в данном случае константы, на весь ранг возможных цифр множителя и осуществить корректное суммирование полученных частичных произведений. Таблица произведений множимого записывается во фрагмент памяти на ПЛИС и называется таблицей перекодировок (ТП, Look-up table, LUT).
Для того чтобы осуществить операцию умножения двух двенадцатиразрядных двоичных чисел, одно из которых — константа, необходимо иметь ТП на 16 значений с разрядностью выходного значения 16 (для положи- тельных чисел) и два 16-разрядных сумматора. Реализация такого умножителя на константу приведена на рис. 3.
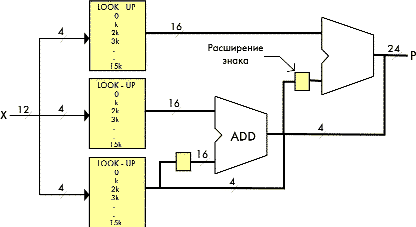
Четыре младших бита выходного произведения нижней на рис. 3 ТП непосредственно в соответствии с алгоритмом функционирования формируют четыре младших разряда окончательного произведения.
Реализация по данному принципу операции умножения отрицательных чисел, представленных в дополнительном коде, не требует каких-либо изменений в технической реализации и не задействует дополнительную специальную логику коррекции; изменится лишь прошивка просмотровой таблицы, адресуемой знаковым битом входного операнда.
Многие ЦФ достаточно просто реализовать в виде КИХ-фильтра. С появлением БИС семейства FLEX8000 и FLEX10K фирмы ALTERA появилась возможность создания высокопроизводительных и гибких КИХ-фильтров высокого порядка. При этом ПЛИС благодаря особенностям своей архитектуры позволяют достигнуть наилучших показателей производительности по сравнению с другими способами реализации ЦФ. Так, реализация ЦФ на базе ЦПОС среднего класса позволяет достигнуть производительности обработки данных порядка 5 млн отсчетов в секунду (MSPS, Million samples per second). Использование готовых специализированных БИС позволяет обеспечить производительность 30–35 MSPS. При использовании ПЛИС семейств FLEX 8000 и FLEX10K достигаются величины более 100 MSPS.
Рассмотрим особенности реализации КИХ-фильтров на базе ПЛИС семейств FLEX8000 и FLEX10K с учетом специфики их архитектуры на примере КИХ-фильтра с 8 отводами (рис. 4). В нем введены следующие обозначения: xn— сигнал на выходе n-го регистра, hn— коэффициент СФ, yn — выходной сигнал. Сигнал на выходе фильтра будет иметь вид:
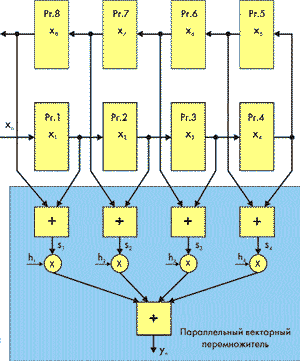
Для обеспечения линейности фазовой характеристики КИХ-фильтра коэффициенты hn СФ фильтра выбираются симметричными относительно центральной величины. Такое построение позволяет сократить число умножителей. Поскольку компоненты вектора h постоянны для любого фильтра с фиксированными характеристиками, то в качестве параллельного векторного умножителя (ПВП) удобно использовать таблицу перекодировок (ТП, LUT, Look-up table), входящую в состав логического элемента (ЛЭ) [1-3] ПЛИС. Работа параллельного векторного умножителя описывается следующим уравнением:
При использовании ТП операция умножения выполняется параллельно. В качестве примера рассмотрим реализацию 2-разрядного векторного умножителя. Пусть вектор коэффициентов h имеет вид:
Вектор сигналов s имеет вид:
Произведение на выходе ПВП принимает вид
Аналогично формируется результат P1в случае 4-разрядных сигналов sn. Частичное произведение P2 вычисляется аналогично, только результат необходимо сдвинуть на 1 разряд влево. Структура четырехразрядного ПВП представлена на рис. 5.
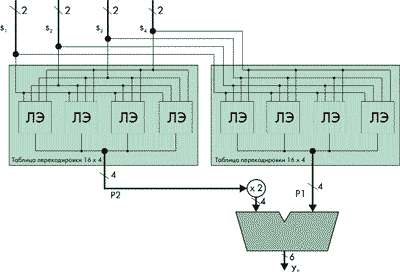
Очевидно, что с ростом разрядности представления данных возрастает размерность ТП, а следовательно, требуется большее число ЛЭ для реализации алгоритма фильтрации. Так, для реализации 8-разрядного ПЛП требуется 8 ТП размерностью 16x8. Операция умножения на 2 легко обеспечивается сдвиговыми регистрами.
Включение сдвиговых регистров на выходах промежуточных сумматоров позволяет обеспечить конвейеризацию обработки данных и, следовательно, повысить производительность. При этом регистры входят в состав соответствующих ЛЭ, поэтому сохраняется компактность структуры, не требуется задействовать дополнительные ЛЭ.
Основным достоинством параллельной архитектуры построения фильтров является высокая производительность. Однако, если число задействованных ЛЭ является критичным, предпочтительнее строить фильтр по последовательной или комбинированной архитектуре. В табл. 3 приведены сравнительные характеристики КИХ-фильтров одинаковой разрядности и порядка, но выполненных по различной архитектуре.
С целью уменьшить числа используемых ЛЭ применяется последовательная архитектура построения фильтра. Так же как и при параллельном построении фильтра, для вычисления частичных P1, P2,…, PN, N=W+1 произведений применяется ТП, W — разрядность данных. Такой ЦФ обрабатывает только один разряд входного сигнала в течение такта. Последовательно вычисляемые частичные произведения накапливаются в масштабирующем аккумуляторе (МА). МА обеспечивает сдвиг содержимого вправо на один разряд каждый такт. После W+1 тактов на выходе появляется результат. Блок управления обеспечивает формирование управляющих сигналов, обеспечивающих корректное выполнение операций.
Комбинированная архитектура является компромиссом между экономичностью и производительностью. В этом случае применяются как последовательные, так и параллельные регистры. В результате распараллеливания вычислений обеспечивается несколько большая производительность, чем у последовательного фильтра.
Одним из эффективных способов повышения производительности фильтра является конвейеризация. В случае если длина вектора S не является степенью двойки, используются дополнительные регистры для обеспечения синхронизации. С целью построения фильтров более высокого порядка используют последовательное соединение фильтров (каскадирование) меньшего порядка.
Увеличение разрядности данных требует обеспечения большей точности вычислений и разрядности коэффициентов. Увеличение разрядности данных на один бит требует использования дополнительной ТП при параллельной архитектуре и увеличения на один такт времени фильтрации при последовательной архитектуре. При этом для обеспечения достаточной точности представления данных для фильтра 32-го порядка требуется 19 разрядов длины выходного слова при 8-разрядных входных данных.
Построение фильтра нечетного порядка достигается удалением одного из регистров сдвига. Если применять не сумматоры, а вычитатели, то легко реализовать фильтр с антисимметричной характеристикой.
Довольно легко реализуются фильтры с прореживанием или, наоборот, с интерполяцией отсчетов. При проектировании прореживающего фильтра обеспечивается покаскадное уменьшение тактовой частоты, что позволяет существенно снизить энергопотребление. Интерполирующий фильтр выполняет противоположную операцию — увеличение частоты выборки в определенное число раз. Одним из способов реализации такого алгоритма является дополнение отсчетов нулями.
Возможности архитектуры ПЛИС семейств FLEX позволяют реализовать двумерные фильтры для обработки изображений, а также решетчатые структуры.
Для проектирования фильтров необходим набор специализированных программных средств, позволяющих синтезировать требуемую системную функцию фильтра, провести моделирование его работы, а также библиотеки параметризируемых мегафункций, содержащих реализации типовых структур ЦФ.
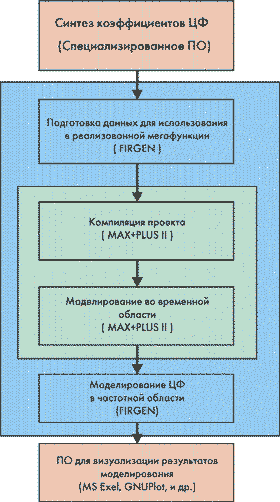
Фирма ALTERA предоставляет в составе Altera DSP Design KIT программный продукт Firgen. В функции программы Firgen входит моделирование КИХ-фильтра с заданными коэффициентами, а также генерация файлов, предназначенных для реализации фильтра штатными средствами пакета MAX+Plus II. Для построения отклика фильтра, полученного в результате моделирования средствами Firgen, можно использовать либо пакет Microsoft Excel, либо входящий в состав Altera DSP Design KIT продукт GNUplot. Схематически процесс разработки фильтра представлен на рис. 6.
Включение сдвиговых регистров на выходах промежуточных сумматоров позволяет обеспечить конвейеризацию обработки данных и, следовательно, повысить производительность. При этом регистры входят в состав соответствующих ЛЭ, поэтому сохраняется компактность структуры, не требуется задействовать дополнительные ЛЭ.
При реализации операции умножения на константу и возведения в степень целесообразно использовать конструкцию TABLE языка AHDL. Как показывает сравнение, такое построение позволяет обеспечить более компактную и быстродействующую реализацию. Ниже приводится пример такой конструкции.
TABLE
net[11..1] => out[15..1];
B»0000000XXXX» => B»000000000000000»;
B»00000010000» => B»000000101011101»;
B»00000100000» => B»000001010111010»;
.
.B»11111110000» => B»010011100001101»;
B»00000010001» => B»010011100001110»;
End TABLE;
В следующем занятии мы продолжим рассмотрение реализации вычислителей на современной элементной базе.
Литература
- Угрюмов Е. П. Цифровая схемотехника. СПб.: БХВ. 2000.
- Стешенко В. Б. Школа схемотехнического проектирования устройств обработки сигналов // Компоненты и технологии, № 3–6, 2000.
- Стешенко В. Школа разработки аппаратуры цифровой обработки сигналов на ПЛИС.
- В.Стешенко. ПЛИС фирмы ALTERA: проектирование устройств обработки сигналов. М.: Додека, 2000.
|


