|
Андрей Прохоренко
DSP + PCI = ПЛИС
Все больше появляется задач по скоростному вводу потоков данных в компьютер. Тут и задачи связи, и обработка видеосигналов, и многое другое, что требует высокой производительности. Обычно компьютер не успевает обрабатывать поток данных в его память напрямую, и из-за этого этот поток фрагментируется, данные теряются, а самый быстродействующий компьютер работает не быстрее арифмометра. Выходом из положения являются специализированные DSP-предпроцессоры, которые ставятся на входе. Цель — сжать информацию, отсеять ненужные данные, которые лишь занимают драгоценное время и ресурсы на передачу. Некоторые вопросы построения таких, особо быстродействующих предпроцессоров и будут рассмотрены в данной статье.
Быстродействие — это, пожалуй, одна из главных характеристик DSP-процессоров. Она определяет границу скоростей поступления данных и сложности алгоритма обработки. Последние достижения в повышении производительности классических DSP, безусловно, впечатляют. Но предел изобретательства в рамках последовательной машины становится все ощутимее. Например, чтобы задать параллельное выполнение нескольких действий одновременно, производители вынуждены использовать шины передачи данных с очень большим количеством бит как внутри чипа DSP, так и вне его. Это резко усложняет, удорожает конструкцию и вообще имеет конструктивный предел. Так, например, фирма TI поставила своеобразный рекорд: ее макроинструкция в новом кристалле DSP уже имеет ширину 256 бит, причем в них может быть упаковано до 8 параллельно выполняемых действий. Может, но при особом искусстве программиста, вооруженного специальным инструментом оптимизации кода. Должно очень сильно повезти, чтобы алгоритм обработки «развалился» без холостых выравнивающих пауз, на восемь синхронно протекающих процессов. Реально же, по-видимому, можно ожидать не более 2–3-кратного запараллеливания действий. По оценкам специалистов фирмы ALTERA классические процессоры DSP допускают предел скорости поступления сигнала для типичных алгоритмов КИХ- фильтрации примерно в 25 Msps (миллионов замеров в секунду). Скорость поступления данных не следует путать с производительностью по инструкциям (измеряется в Mips — миллионах инструкций в секунду), который фигурирует в характеристиках процессора DSP. Знание производительности по инструкциям явно недостаточно, чтобы ответить на вопрос: удастся ли пользователю реализовать его алгоритм обработки данных, поступающих с такой-то скоростью? Все зависит от критического цикла, который, как правило, образуется из множества инструкций. При малейшем отступлении от хрестоматийности алгоритмов DSP, например преобразование Фурье, эффективность упаковки нескольких действий в одной макроинструкции резко падает, критический цикл удлиняется и производительность системы катастрофически падает. Разработчик в этом случае вынужден устанавливать и второй, и третий кристалл DSP. Кстати, такое развитие событий предусмотрено самими изготовителями, которые снабжают чипы скоростными узлами для каскадирования. О конечной сложности, надежности и стоимости таких систем предоставляем судить читателю. Хорошей альтернативой и своеобразным выходом из тупика является здесь применение больших вентильных матриц (ПЛИС) в задачах цифровой обработки сигналов. Прикладные проекты на ПЛИС являются машинами параллельного действия, и поэтому здесь уже нет жестких ограничений на производительность и нестандартность алгоритмов. ПЛИС принимают от классических DSP последовательного действия эстафету примерно у черты 25 Msps и идут дальше в область более высоких скоростей поступления данных.
К вопросу о быстродействии относится и способ обмена данными между DSP предпроцессором и основным компьютером. Канал передачи данных здесь может оказаться узким местом всей системы. Сейчас наиболее распространена в промышленности и стала уже стандартом высокоскоростная шина PCI. В частности, она применяется для наращивания ресурсов в компьютерах путем установки дополнительных устройств. Пропускная способность шины PCI, даже в ее простейшем варианте 32-бит 33 МГц, достаточно велика. Она, например, позволяет напрямую, по DMA, заполнять внутреннюю память компьютера значениями видеосигнала от радиолокатора квантуемого с частотой 40 МГц. Если же предпроцессор производит еще и сжатие этих данных перед их засылкой в память, то запас пропускной способности шины становится весьма значительным и основной процессор компьютера практически не притормаживается. Ранее использовавшаяся в компьютерах шина ISA с такой задачей не справлялась. И тем не менее автору не известна ни одна модель классического DSP со встроенным интерфейсом шины PCI, а ISA — пожалуйста. Для их сопряжения с шиной PCI требуется дополнительный и весьма непростой контроллер. В то же самое время этот контроллер может быть интегрирован в прикладной проект на ПЛИС без дополнительных внешних схем и напрямую подключаться к выводам разъема PCI. Преимущества ПЛИС и в этом аспекте достаточно ощутимы.
Рассмотрим теперь вопрос гибкости применения и сопровождения таких предпроцессоров. Как правило, начальная загрузка программы в классический DSP, или конфигурации в ПЛИС, производится автоматически при включении питания считыванием кодов из внешнего ПЗУ. Это нельзя признать удобным для предпроцессоров DSP в составе компьютера, поскольку любая модификация приводит к вскрытию этого компьютера, извлечению ПЗУ, его перезаписи и помещению всего обратно на свое место. Мероприятие, прямо скажем, далеко не для всех. Пользователи же компьютерных систем обычно хотят гораздо большую оперативность и простоту в смене алгоритмов, повышенную гибкость в настройке под их индивидуальные требования. Идеальным здесь считается загрузка программного обеспечения в предпроцессор из файла на винчестере. Сопровождать такие изделия становится особенно удобно с помощью электронной почты без выезда на место эксплуатации. Но здесь ситуация с применением, как классических DSP, так и предпроцессоров на базе ПЛИС, оказалась малоутешительной — начальная загрузка этих устройств с винчестера, тем более через шину PCI, оказалась чрезвычайно редким явлением. Однако, как будет показано ниже, реализация предпроцессоров с такими жесткими требованиями на гибкость оказывается технически более простой в случае применения ПЛИС.
Перейдем теперь к предметному описанию встретившейся нам задачи DSP и покажем на ее примере тот ряд характеристик и условий, при которых преимущество больших ПЛИС в предпроцессорах DSP становится особо очевидным. Речь пойдет о плате экстрактора радиолокационных сигналов, вставляемой в обычный персональный компьютер. Плата имеет аналоговый высокочастотный вход для видеосигнала от локатора. Квантование производится 10 бит АЦП с частотой 40 МГц, что соответствует разрешению около 6 м на расстоянии до 40 км. Плата вставляется в PCI слот персонального компьютера. Ее задача — выделять полезные сигналы(сжатие данных), опрашивать азимутальные датчики локатора и постоянно обновлять в памяти компьютера картину кругового зондирования. Засылка сжатой информации данных в память компьютера производится по DMA. Сам же компьютер занят в основном задачами прорисовки радиолокационной обстановки, сопровождением целей, коммуникацией с удаленным диспетчером и т. д.
Анализ алгоритмов а экстракции показал, что устройство должно состоять из порядка семи самостоятельных и работающих в параллель узлов. Причем ни один из них не подпадал под хрестоматийную задачу DSP, когда надо быстро умножать и складывать. Так сразу рухнули надежды применить классический DSP последовательного действия в нашем случае. Кратко перечислим некоторые из этих узлов обработки.
1.Узел восстановления нулевого уровня видеосигнала. Он устраняет искажения, вносимые входной цепью с разделительным конденсатором. С частотой 40 МГц этот узел выделяет локальные минимумы и производит вычитания со знаком.
2.Узел вычисления средних значений видеосигнала на последовательности временных интервалов зондирования. Здесь требуется не простое суммирование амплитуд, а с отбраковкой шумовых артефактов и больших целей. В результате выборка оказывалась нерегулярной, могла заканчиваться в произвольном месте временного интервала. Соответственно, промежуточные результаты незаконченной выборки приходится запоминать, чтобы на следующем зондировании возобновить накопление среднего. Этот довольно сложный алгоритм реализуется с тактом в 40 МГц.
3.Узел экстракции отраженных импульсов представляет собою амплитудный компаратор с переменным на каждом временном интервале порогом. Порог выбирается из памяти, как результат автоподстройки по результатам предыдущего зондирования. Кроме того, компаратор учитывает и свои срабатывания на предыдущем зондировании в виде временной маски. Компаратор выделяет как восходящий, так и падающий фронт импульса с временным разрешением в 25 нс. Между ними производится оцифровка амплитуд с задаваемым прорежением, что дает возможность прорисовывать на экране подобие профиля объектов. Именно этот узел и производит основное сжатие информации простым отбрасыванием ненужных замеров. Такое сжатие оценивается примерно как 500:1. На столько же происходит высвобождение шины и процессора в компьютере по сравнению с обычными платами быстродействующих АЦП, которые вводят все замеры без исключения.
4.Память FIFO с раздельной синхронизацией по записи и по считыванию. В нее, по сигналу компаратора, записываются все временные, амплитудные и азимутальные засечки сигналов. Считывание производит контроллер DMA, подключенный к шине PCI через специальный контроллер.
5.Узел измерения азимута. Он производит действия по устранению дребезга счетных импульсов от локатора, фильтрует удвоения и пропадания импульсов, возникающие на длинных кабелях подключения. Кроме того, этот узел имеет встроенный программно управляемый умножитель частоты, который нормализует импульсный сигнал по частоте и делает его всегда 4096 импульсов на оборот локатора, независимо от характеристик азимутальных датчиков локатора.
6. Диспетчер событий и блоки памяти, в которых хранятся все промежуточные результаты, маски и настроечные параметры. Диспетчер событий также производит простейшие вычислительные операции для адап- тивного управления порогами селектирования импульсов.
7. Узел DMA и контроллер PCI для взаимодействия с основным компьютером.
Все эти узлы удалось интегрировать на одном кристалле загружаемой матрицы EPF10 KЕ50 фирмы ALTERA, где они и работают в параллель.
Следует более подробно остановиться на приемах, которые обеспечивают уникальную гибкость данному изделию. Речь пойдет о загрузке файла конфигурации с винчестера компьютера, через его шину PCI, в ПЛИС. Здесь принципиальным является наличие в конструкции узла жесткой логики, которая заведует загрузкой ПЛИС с шины PCI. В качестве таковой можно было бы применить готовые PCI-контроллеры, например, самые простые— Target. Однако их интерфейс не рассчитан на загрузку ПЛИС, что приводит к установке дополнительных сопрягающих схем.
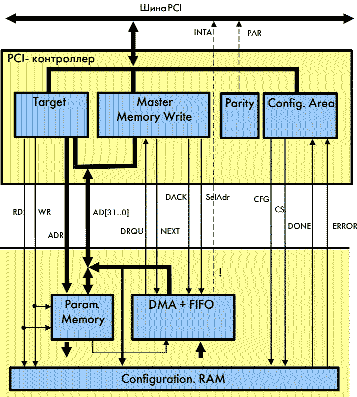
Поэтому было решено разделить весь проект с шиной PCI на две ПЛИС. Одна из матриц, с минимумом ресурсов, программируется жестко и обеспечивает простейший протокол Master-Target плюс статические порты для специфических сигналов загрузки конфигурации другой половины проекта. По существу, был исполнен PCI-контроллер с важными добавочными функциями. Вторая матрица, со значительно большими ресурсами и загружаемой конфигурацией, содержит основную часть проекта, оперативно загружается с винчестера через первую ПЛИС и тем самым обеспечивает уникальную гибкость применения. На рис.1 представлено распределение узлов PCI-проекта между двумя ПЛИС, обе производства фирмы ALTERA.
PCI-контроллер размещается на кристалле EPM7256A фирмы ALTERA, в малогабаритном корпусе TQFP-144 с питанием от +3,3В. Он рассчитан на 32-битную шину данных и частоту 33 МГц. Допускает подключение как к +3,3В шине PCI, так и к +5В. После проведения стандартных операций Plug-and-Play контроллер способен производить загрузку файлов конфигурации в ПЛИС серии фирмы ALTERA. Статические сигналы для проведения загрузки (nCFG, DONE, nERROR) отображаются на резервные биты командного слова и слова состояния в служебной зоне PCI-контроллера (Config. Area). Загрузка производится по параллельной пассивной асинхронной схеме (PPA), по тем же линиям (AD[7..0], RD, WR), которые после загрузки будут участвовать в передаче данных между основной ПЛИС и контроллером. Требуется специальный программный драйвер, который производит загрузку файла с винчестера в конфигурационную память ПЛИС (Configuration RAM).
В процессе Plug-and-Play PCI-контроллер запрашивает у системы адресное пространство памяти максимальным размером 1 Мбайт и отображает туда все регистры управления устройством (PARAM. MEM). Сами регистры физически размещаются в основной ПЛИС уже после ее конфигурации. Фактическое их количество, назначение и размер относятся к переменной части проекта и не ограничивают гибкость. Доступ в зону параметров со стороны PCI-шины обеспечивает Target-узел контроллера. Он преобразует протокол шины в простейший микропроцессорный интерфейс, состоящий из двунаправленной 32-битной шины данных, отдельной шины адресов и двух стробирующих сигналов: записи и чтения. Дополнительно узел Target обеспечивает нужные для загрузки ПЛИС длительности сигналов.
В контроллер встроен минимально необходимый узел PCI-Master, который заведует операциями «DMA запись в память». Большая же часть контроллера DMA отнесена в изменяемую часть проекта, в загружаемую ПЛИС. Наилучшие результаты по простоте и быстродействию получаются при использовании на месте загружаемой ПЛИС матриц фирмы ALTERA из серии FLEX10KE. Эта серия имеет структуру со встроенными двухпортовыми блоками памяти, из которых просто создать память FIFO
с асинхронными записью и чтением. Такой тип буфера можно считать идеальной развязкой процессов обработки сигнала и выгрузки результатов.
Взаимодействие при DMA между двумя частями проекта происходит по следующему набору сигналов: шина данных 32-бит, запрос на DMA, подтверждение доступа DACK, сигнал выборки начального адреса SelAdr и сигнал переключения на следующую порцию данных NEXT. Комбинации сигналов DACK и SelAdr определяют начало кадра, интервал выдачи из ПЛИС адреса, интервал посылки из ПЛИС данных в режиме Burst и окончание кадра. Master узел PCI-контроллера реализует Burst режим с одним циклом ожидания, в течение которого производится переключение по сигналу NEXT данных в ПЛИС и транспортировка их через контроллер на шину PCI. Сигнал NEXT не только выбирает новую порцию данных из FIFO, но и инкрементирует встроенный в ПЛИС счетчик адреса DMA. Если по каким-либо причинам фаза передачи данных в шину PCI заканчивается неудачно, то сигнал NEXT не вырабатывается и следующая попытка DMA будет произведена с прежнего адреса. Управление DMA осуществляется через регистры из зоны параметров. Схема управления относится к изменяемой части проекта и может реализовать самые разнообразные варианты: с остановкой и выдачей прерывания INTA по достижении конца сегмента памяти DMA, без остановки или без сигнала прерывания.
При разбиении PCI-проекта на две части, фиксированную и изменяемую, мы стремились к максимальному упрощению и удешевлению фиксированной части проекта — PCI контроллера. Чтобы уложиться в малогабаритный корпус TQFP c 144 выводами и использовать самую низкую скоростную градацию матрицы, пришлось пойти на незначительные в практическом плане ограничения. Они заключаются в следующем:
1. Обмен всегда полными 32-бит словами при тактовой частоте 33 МГц. Для повышения частоты до 66 МГц можно использовать другую, более высокую скоростную градацию матрицы, но это резко удорожит конструкцию.
2. PCI-Target узел не работает в Burst-режиме: разрешена только одна порция данных в кадре.
3. Контроллер не проверяет четность поступающих данных и не вырабатывает сигналы PERR и SERR, но он вырабатывает сигнал четности PAR, сопровождая им передачу своих данных.
4. Узел PCI-Master рассчитан только на операции по шине «DMA запись в память».
5. Узел PCI-Master вставляет один такт ожидания на фазу передачи в Burst-режиме.
В современной жизни очень важной является защита интеллектуальной собственности. В нашем случае — особенно, потому что электрически конструкция на базе ПЛИС совершенно прозрачна, а главная ценность — загружаемый файл конфигурации — доступен на винчестере. Тем не менее размещение части прикладного проекта в матрице с фиксированной прошивкой, которая закрыта битом секретности, позволяет предотвратить подавляющее большинство неприятностей.
В принципе представленная конструкция достаточно универсальна и подходит для самых разнообразных случаев построения предпроцессоров сигналов в составе системы с шиной PCI. Это дает нам основание предложить данную плату как универсальный DSP-конструктор. Конструктор рассчитан на обработку видеосигналов с частотой квантования 40 МГц и выше, сжатие потока данных и ввод их по DMA в память компьютера. Кроме того, имеются дискретные входы и выходы для управления и мониторинга источника видеосигнала.
|


